DeconNet에 대해 알아보자 원 논문은 여기에서 확인 할 수 있다.
Abstract
- VGG 16 레이어 네트워크에서 채택된 convolution layer위에 네트워크를 학습시킴
- Deconvolution Network는 Deconvolution 및 Unpooling layer로 구성
- 기존의 Fully Connected Network가 가지고 있는 한계점을 극복하기 위해 심층 deconvolution네트워크와 proposal-wise prediction을 통합하였다.
- 결과, Detail한 측면과 Mutiple scales한 측면에서 기존 대비 많은 효과가 있었다.
Introduction
Convolution Neural Network(CNN)은 image classification, object detection, instance segment, visual tracking, action recognition과 같은 다양한 시각적 인식 문제에 널리 사용된다. 이에 CNN을 사용하여 semantic segmentaion, human pose estimation등에 적용하기 시작한다.
최근의 sematic segmantation알고리즘은 CNN을 기반으로 구조화된 픽셀 단위의 labeling 문제를 해결하기 위해 공식화 되고 있다. 분류를 위해 구축된 기존 CNN 아키텍처를 fully convolution network(FCN)으로 변환한다.
이미지의 모든 local영역을 분류하여 네트워크에 대략적인 레이블 맵은 얻고, 픽셀수준 레이블링을 위해 이중 선형보간으로 구현되는 간단한 deconvolution을 수행한다. 세부적인 분할을 위해 conditional random field(CRF)를 출력맵에 선택적으로 적용한다.
Fully Convolution Networks의 한계
FCN 기반 메소드의 주요 장점은 네트워크가 전체 이미지를 입력으로 받아들이고 빠르고 정확한 추론을 수행한다는 것이지만 한계가 존재한다.
- 네트워크에 미리 정의된 고정된 Receptive field를 가진다. → receptive field 보다 상당히 크거나 작은 경우에 대해서는 잘 못맞추는 경향을 보인다
- object가 큰 경우 : object의 부분적인 정보들만을 가지고 분류하게 되는 문제점이 발생 (e.g. 버스를 분류할 때, 버스 전체를 보는 것이 아니라 앞면, 유리 등 부분적인 특징을 가지고 분류하게 된다.)
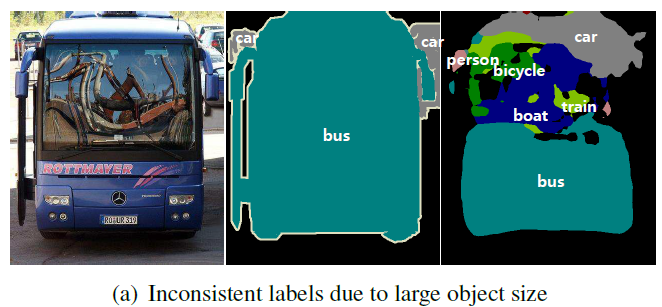
- object가 작은 경우: 일관성없게 분류하는 문제점을 가지고 있다. 종종 무시하거나 배경으로 예측하는 경우
- 위 한계점은 FCN 논문에서 Skip Architecture으로 극복하려고 했던 점들이지만, 충분한 해결책이 아니고 details 과 sematics 측면에서 trade - off를 가진다.

- object의 detail한 구조를 잃어버리거나 포괄적인 모습으로 대체한다.
- deconvolution layer에 대한 입력인 라벨 map이 coarse하고, deconvolution의 절차가 지나치게 simple하기 때문
- 원래 FCN에서 label map은 크기가 16x16에 불과하며 bilinear interpolation을 통해 원래 입력 크기로 segmentation 결과를 생성하도록 deconvolution되어 있지만, 실제로는 deconvolution이 존재하지 않기 때문에 좋은 성과를 달성하기 어렵다. → 최근에는 CRF를 사용하여 이 문제를 개선한다.
본 논문의 기여는 다음과 같다.
- deconvolution, unpooling 및 ReLU 층으로 구성된 심층 deconvolution 네트워크를 학습. (semantic segmentation을 위한 deconvolution 네트워크를 처음 시도)
- 훈련된 네트워크는 최종 instance-wise segmentation 얻기 위해 개별 객체 proposals 에 적용되며, 원래의 FCN 방법에서 발견된 scale 문제(객체크기)가 없고 객체의 내부 세부사항을 식별함.
- PASCAL VOC 2012 증강 데이터셋에 대해 훈련된 deconvolution 네트워크를 사용하여 탁월한 성능을 달성하고, FCN 기반 방법과 관련하여 알고리즘의 이질적이고 상호 보완적인 특성을 활용하여 FCN과의 앙상블을 통해 최고의 정확도를 달성.
⇒ PASCAL VOC 2012 벤치마크에서 SOTA
System Architecture
Architecture
네트워크는 크게 두 부분으로 나눌 수 있다.

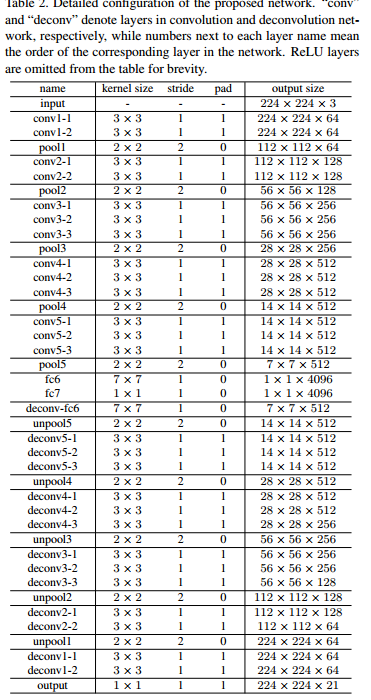
- Convolution : input image의 feature를 추출해서 multidimensional feature representation으로 변환하는 feature extractor
- 위의 구성은 VGG 16-layer net에서 마지막 classification layer를 제거한 것이고, 결국 Convolution networks는 13개의 convolution layers으로 구성되어있고 ReLU 와 Pooling이 convolutions 사이에 수행됨. 마지막으로 2개의 fully connnect layers (1x1 convolution)으로 class-specific projection을 수행함
- Deconvolution : convolution network으로부터 추출된 feature를 object segmentation으로 생성
- convolution network의 mirror버전으로 unpooling, deconvolution 그리고 ReLU layers으로 구성되어 있다.
→ 네트워크의 최종 출력은 입력 이미지와 동일한 크기의 확률 map이며, 각 픽셀이 미리 정의된 클래스 중 하나에 속할 확률을 나타낸다.
Deconvolution Network for Segmentation
Unpooling
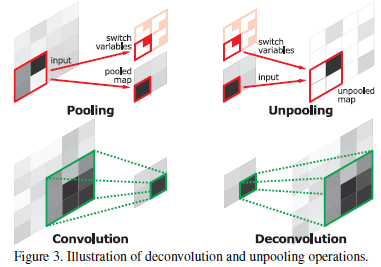
Convolution에서 Pooling은 대표값을 추출해서 noisy activation을 걸러주는 역할을 하지만, spatial information을 잃어버리는 문제점을 가지고 있음. 이러한 문제를 해결하기 위해서, 아래의 그림과 같은 Pooling 시의 활성화된 위치를 기억하고 해당 값을 복원하는 방법을 사용
Convolution Network의 Pooling은 noisy activation을 필터링 해주는 역할을 한다. 상위 계층에서 강력한 activations만을 유지하여 분류에 도움이 되지만, receptive field 내의 spatial information는 pooling 중에 손실된다.
- 이는 Semantic Segmentation에 필요한 정확한 localization에 매우 중요할 수 있음
⇒ Unpooling : pooling 시의 활성화 된 위치를 기억하고 해당 값을 복원하는 방법을 사용
이러한 전략은 input object의 구조를 기억하는데 매우 유용하다.
- PyTorch
- PyTorch에서는
명령어를 통해서 위치를 추출하고,nn.MaxPool2d(2, stride=2, ceil_mode=True, return_indices=True) -
unpooling시에 해당 인덱스를 넣어줌으로서 구현가능함unpool1 = nn.MaxUnpool2d(2, stride=2), unpool1(h, pool1_indices)
Deconvolution
Unpooling layer의 output은 크지만, sparse activation map 이라는 문제점이 있다(대부분의 값이 0으로 비활성화 되어있음). deconvolution layer는 이러한 sparse를 dense activation map 으로 조밀하게 만드는 특징을 가지고 있다.
그러나, filter window 내의 다중 입력 activation을 단일 activation에 연결하는 convolution 계층과 달리, deconvolution 계층은 단일 입력 activation을 다중 출력과 연관시킨다.
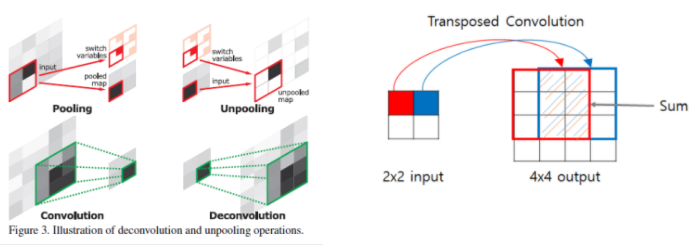
이러한 deconvolution layers는 unpooling layer의 size를 유지하므로, input object의 모양을 재구성한다. convolution layer와 유사하게 deconvolution layer의 hierarchical structure는 different level of shape details를 포착하기 위해 사용된다.
- lower layer의 필터는 전반적인 모양
- higher layer는 디테일한 모양을 잡는 역할
- 전체 구조
Analysis of Deconvolution Network

Deconvolution Network의 Deconvolution과 Unpooling에 의해서 활성화된 activation map을 보면 위와 같다.
coarse activation maps 에서 수행된 FCN의 단순 Deconvolution과 달리, 우리의 알고리즘은 Unpooling, Deconvolution 및 rectification의 연속적인 연산에 의해 밀도 있는 픽셀 단위 probability map을 얻는 Deep-Deconvolution 네트워크를 사용하여 object segmentation mask를 생성
- (b), (d), (f), (h), (j)와 같은 Deconvolution의 결과는 dense
- (c), (e), (g), (i)와 같이 Max unpooling의 결과는 sparse
- lower layer은 전반적인 특징 (location, shape, region)을 잡음
- higher layer는 복잡한 패턴을 잡음

위의 그림과 같이 FCN에 비해 디테일한 모습이 많이 살아나는 장점을 보인다.
Training
네트워크는 매우 deep하고, 많은 매개변수를 포함하고 있지만, sematic sementation을 위한 training example의 수는 네트워크의 크기에 비해 상대적으로 적다( 총 12031 PASCAL training 및 validation 이미지 )
적은 수의 example로 deep한 network를 training하는 것은 어렵기 때문에 다음의 아이디어를 사용했다.
Batch Normalization
DNN은 Internal-covariate-shift 때문에 최적화하기 어렵고, 이를 해결하기 위해서 batch normalization을 적용하였다.
- Internal-covariate-shift
- 각 layer의 입력 분포는 이전 layer의 매개 변수가 업데이트 됨에 따라 훈련중 iteration에 따라 변화한다. layer 간 전파를 통해 분포의 변화가 증폭되기 때문에 매우 깊은 네트워크를 최적화 하는 데 문제가 있다.
- → Batch normalization을 사용하여 모든 레이어의 입력 분포를 normal-gaussian 분포로 정규화하여 Internal-covariate-shift를 줄인다.
Two-stage Training
비록 batch normalization에 의해 local optimal을 탈출하는데 도움을 주지만, semantic segmentation의 공간은 학습 데이터에 비해 크고 instance segmentation을 수행하는 deconvolution의 장점이 사라진다.
이를 방지하기 위해 2 stage의 학습을 진행한다.
- First stage (쉬운 데이터로 학습)
- Ground-truth annotation을 사용해 object가 정중앙에 위치하도록 bounding box를 생성하고 이를 crop하는 방식으로 학습 데이터(object instance)를 구성하여 학습한다.
- Object의 위치 및 크기 변화를 제한함으로서 search space를 줄일 수 있기 때문에, 학습이 더 쉬워지고 적은 데이터로도 네트워크를 훈련시킬 수 있게 된다.
- Second stage (어려운 데이터로 학습)
- **Edge Boxes**에서 제안한 방법을 통해 proposal들을 생성하는 방식으로 학습 데이터를 구성하여 학습한다.
- 이때, 실제 정답에서의 segmentation(ground-truth segmentation)과 잘 겹치는 proposal들만을 사용한다. (IoU가 0.5이상인 proposal들)
- Object의 위치 및 크기가 많이 달라지기 때문에 학습은 더 어려워지지만, proposal의 misalignment에 대해 네트워크가 더욱 robust하도록 만들어준다.
일반적인 이미지 분류는 테스크가 쉽지만, Segmentation은 픽셀단위의 분류를 하기에 Optimal을 찾는 과정이 더 어렵고 local optimal을 탈출하기가 힘듦
- 그렇기에, 1stage에서는 하나의 객체만 포함하도록 해서 쉬운 테스크를 진행하고 2stage에서는 좀 더 어려운 이미지로 학습을 진행
Inference
DeconvNet은 개별의 instance에 대해 sematic segmentation을 수행한다. 개별 instance를 생성하기 위해 input image를 window sliding을 통해서 충분한 수의 candidate proposals를 만든다. 이후, 이에 대해 semantic segmentation을 수행하고 proposals에 대해서 나온 모든 결과를 aggregate해서 전체 이미지에 대한 결과를 생성한다.
추가적으로, FCN과 앙상블 시 성능이 향상된다.
Aggregating Instance-wise Segmentation Maps
몇몇 Proposals는 정렬이 잘못되거나, 배경이 어수선하면 부정확한 예측을 가질 수 있으므로 aggregation을 통해 이러한 noise를 억제할 수 있다.
Pixel-wise Maximum or average를 통해서 충분히 robust한 결과를 만든다.

원본 이미지 공간의 class conditional probability maps은 aggregation map에 softmax 함수를 적용하여 얻을 수 있다.
이후, output map에 fully-connected CRF를 적용시킨다.
Ensemble with FCN
Deconvolution Network에 기초한 알고리즘은 FCN의 보완적 특성을 가진다.
DeconvNet은 fine-details를 잘 잡는 반면에, FCN은 overall shape를 추출하는데 강점을 가지고 있다.
instance wise prediction은 object의 various scales을 다루고, FCN은 coarse scale에서의 context를 잡는데 강점이 있음
둘을 독립적으로 시행후에 Ensemble 하고, CRF를 적용하면 가장 좋은 결과가 나옴
Experiments
- PASCAL VOC 2012 segmentation dataset과 Microsoft COCO 으로 실험한 결과 아래와 같이 좋은 결과를 얻음
- Optimization은 SGD를 이용하고, learning rate, momentum, weight decay는 각각 0.01, 0.9, 0.0005으로 설정. ILSVRC 데이터셋으로 pre-trained된 모델을 사용했으며 deconvolution networks는 zero-mean Gaussians으로 initialize 함. 또한, drop out을 제거하고 batch normalization을 활용
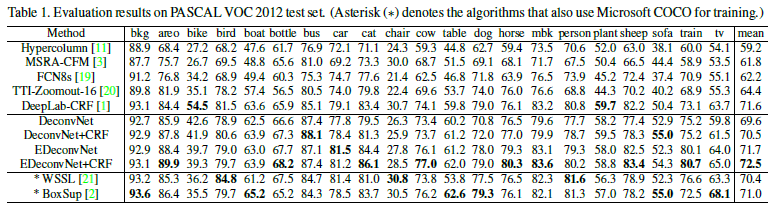
- FCN-8s와의 앙상블 및 CRF를 적용한 모델(EDeconvNet + CRF)이 가장 높은 성능을 기록하였다.
- **CRF**는 약 1%의 성능을 향상시켜 주었다.
- FCN-8s와의 앙상블(EDeconvNet)은 단일 모델(FCN8s, DeconvNet)의 성능을 크게 향상시켜 주었다.

- Figure 7은 DeconvNet, FCN, EDeconvNet, EDeconvNet + CRF를 각각 비교한 것이다.
- FCN은 아주 크거나 작은 object에서 성능이 좋지 못하다. (Figure 7(a))
- DeconvNet은 FCN보다 fine segmentation을 생성할 수 있고 multi-scale object를 다룰 수 있지만, 가끔 noisy한 결과(Figure 7(b))를 보인다.
- EDeconvNet부터는 FCN과 DeconvNet보다 좋은 성능을 보인다. (Figure 7(a), 7(b))
- FCN, DeconvNet에서 정확하지 못한 prediction이 있는 경우에도, EDeconvNet에서 좋은 성능을 보이는 경우도 있었다. (Figure 7(c))
- CRF를 추가한 경우 성능이 향상되기는 하지만, 눈에 띄는 정도는 아니다.
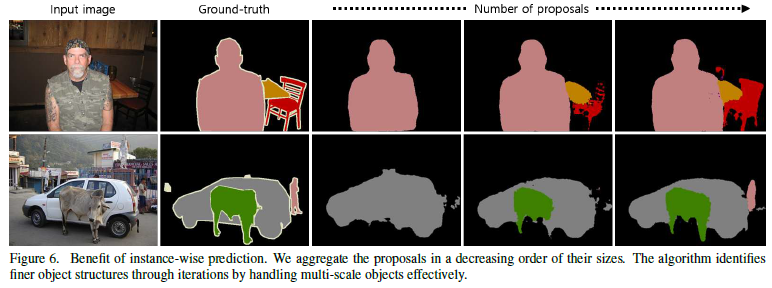
- 또한, proposals의 수를 늘릴 수록 결과가 좋아지는 것을 볼 수 있음
Reference
'Deep Learning > Computer Vision' 카테고리의 다른 글
| Semactic Segmentation 기초 개념 (0) | 2021.12.15 |
|---|

댓글