Deep Learning/Natural Language Processing
Transformers 가족 (BERT vs GPT vs GPT2)
hyez
2021. 6. 1. 23:31
Transformers 가족
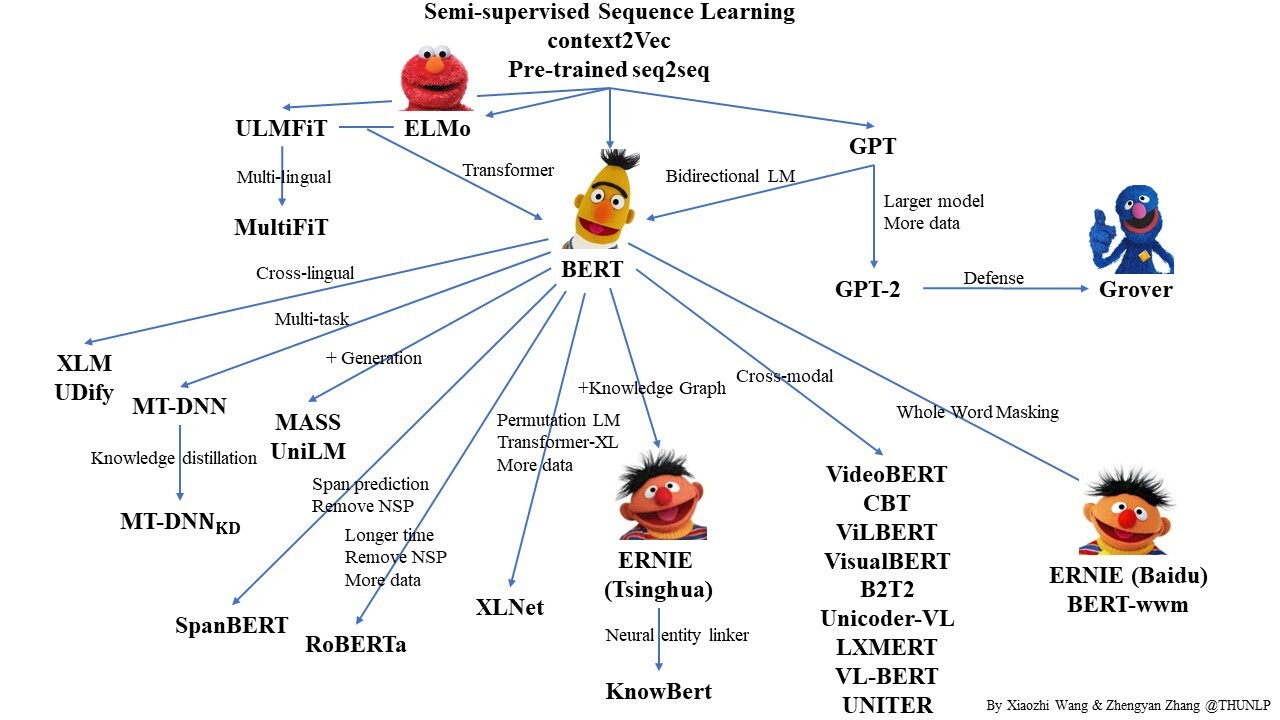
BERT
- 언어모델?(Language Model, LM)
- 언어들의 시퀀스에 대한 확률분포
- 비지도 학습
- bidirectional
- MLM
- NSP
- [CLS]
- [SEP]
- fine-tuning 시 pre-train한 모델과 weight를 동일하게 사용
GPT
- 비지도 학습
- MLM, NSP X → 전통적 언어 모델링(AR, Autoregressive 방식)
BERT와의 차이점
- 실제 문제를 대상으로 학습을 진행할 때도 언오 모델을 함께 학습한다.
- 손실함수 loss가 2개 : 실제 학습 손실값 ($loss_1$) + 언어모델 손실값($loss_2$)
- 본 학습 문제에 특화된 입력값을 사용
- 다른 pre-train dataset
GPT2
- Layer Normalization의 위치 이동
- 다양한 영역의 텍스트 활용
- BPE
- gluonnlp의 SentencePiece : SKT가 KoGPT를 학습할 때 사용
Language Generate
- Greedy Search
- ↔Sampling
- top-k
- top-p - NucleusSampling(top-k 보다 개연성, 안정성)
- THE CURIOUS CASE OF NEURAL TEXT DeGENERATION