GPT Understands, Too
While GPTs with traditional fine-tuning fail to achieve strong results on natural language understanding (NLU), we show that GPTs can be better than or comparable to similar-sized BERTs on NLU tasks with a novel method P-tuning -- which employs trainable c
arxiv.org
내용 요약
1) 기존의 Descrete prompt search는 prompt의 한 단어의 변화가 성능에 많은 영향을 미침 → prompt를 생성해 내는게 주요한 작업.
2) P-tuning은 pseudo token [P_i]를 prompt encoder(lstm)에 넣어 얻은 embedding tensor h_i로 prompt를 구성
⇒ model의 vocab이 표현가능한 어휘를 넘어 더 좋은 continuous prompt를 찾을 수 있음
Abstract
기존의 GPT를 fine-tuning 해서는 Natural Language Understanding(NLU)에 대해 좋은 결과를 달성하는데에 실패했다. 본 논문에서는 GPT를 trainable continuous prompt embedding을 사용한 새로운 방법인 P-Tuning을 통해 학습함으로써 BERT보다 더 우수하거나 비슷할 수 있음을 보여준다.
performance
- knowledge probing (LAMA) 벤치마크
- GPT는 테스트 동안 추가적인 text 없이 world knowledge를 64%(P@1) 복구하여 이전보다 20% 이상 크게 개선
- SuperGlue 벤치마크
- GPT는 supervised learning에서 유사한 크기의 BERT와 비슷하거나 더 좋은 성능을 달성
P-Tuning이 기여한 점
- GPT뿐만 아니라 few-shot과 supervised setting에서 BERT의 performance를 향상시킴
- Prompt engineering의 필요성을 크게 줄인다. (기존엔 handcraft, discrete token embedding)
⇒ 결과적으로 SOTA
1. Intoduction
Language model을 pre-training 하는 것은 natural language processing에서 성공적인 접근 방법이었다. pre-training하는 동안 language model은 contextualized text representation 뿐만 아니라 문법(grammar), 구문(syntactic), 상식(commonsense), 심지어 world knowledge도 학습함을 통해 알 수 있다.
objective function에 따라 pre-trained language models은 세가지 카테고리로 나눌 수 있다.
- unidirectional language model - Natural Language Generation - e.g. GPT
- bidirectional language model - Natural Language Understand - e.g. BERT
- hybrid language model - combining the first two paradigm - e.g. XLNet, UniLM
오랫동안 연구자들은 GPT style이 NLU작업에서 성능이 떨어지고, 본질적으로 language understanding에 적합하지 않다고 가정했다.
새롭게 등장한 GPT-3와 handcrafted prompt를 사용한 few-shot 및 zero-shot learning에 대한 성능은 아주 성공적이었다. 이는 적절하게 handcraft로 prompt를 만들면 giant unidirectional 언어모델이 NLU에서도 좋은 성능을 얻을 수 있다는 것을 시사한다. 그러나 best-performing prompt를 수작업으로 만든다는 것은 말도 안되는 이야기이며, 비현실적으로 큰 validation set를 필요로 한다.
- prompt emgineering은 test set을 과적합할 수 있고,
- prompt를 잘못 만들면 상당한 성능 저하를 초래하는 adversarial prompt를 만들기도 쉽다.
이러한 문제 때문에 최근 연구는 discrete prompt를 자동으로 검색하는데 초점을 맞추고 있다.
→ 그러나, 신경망은 본질적으로 연속적이기 때문에 discrete prompt는 suboptimal !
- GPT-3의 handcraft prompt

-
- discrete prompt
- token은 discrete
- neural network는 continous
- discrete prompt
P-tuning : GPU와 NLU 어플리케이션 간의 격차를 해소하기 위해 continous space에서 prompt를 자동으로 검색하는 새로운 방법
- pre-trained language model에 대한 입력으로 제공되는 prompt를 위해 parameter update가 거의 이루어지지 않는다.
- 이 후 discrete prompt 검색의 대안으로 gradient descent를 사용하여 continous prompt를 최적화 한다
간단한 P-tuning 만으로도 GPT의 NLU에 개선 효과을 얻을 수 있었음
- LAMA knowledge probing
- P-tuning 기반 GPT는 Precision@1에서 26.2%-41.1% 이득
- LAMA에서 가장 좋은 성능은 64.2%이고, 기존 SOTA(45.2%)를 뛰어 넘음
- SuperGLUE
- few-shot과 supervised learning에서 P-tuning과 fine-tuning을 공동으로 적용(HOW????)
- 동일한 사이즈의 BERT와 비교하였을 때 비슷하거나 더 좋은 성능을 냄
추가적으로 BERT style 모델도 P-tuning의 이점을 얻을 수 있음을 입증
- P-tuning을 사용한 ALBERT가 이전 접근 방식을 능가, SuperGLUE에서 SOTA를 달성
⇒ GPT가 생성만 잘하고 이해는 못한다는 고정관념을 깨트렸다. 또한 language model에서는 이전에 생각한 것 보다 더 많은 world knowledge와 prior task knowledge이 포함되어있음을 시사한다. 또한 P-Tuning은 사전 훈련된 언어 모델을 조정하는 일반적인 방법으로 사용할 수 있다. (fine-tuning을 대체할 만한..)
- GPT는 P-tuning을 통해 NLU에서 BERT만큼 경쟁력이 있을 수 있으며, pre-trained 언어 모델의 성능을 향상시키기도 한다. → NLU에서 GPT style이 과소평가 되었음을 보여준다.
- P-tuning이 few-shot과 fully-supervised setting 모두에서 GPT와 BERT를 향상시키기 위한 일반적이 방법임을 보여줌. P-tuning을 통해 여러 벤치마크에서 SOTA를 능가함을 확인했고 이는 언어모델이 이전에 생각했던 것 보다 더 많은 지식을 내포하고 있는 것을 알 수 있다.

2. Motivation
GPT-3나 DALL-E는 giant model이 인공지능을 더 똑똑하게 만들 수 있는 만병통치약이나 다름없는 것임을 시사한다. 그러나 giant model들은 transfer ability가 취약하다는 것이 문제가 된다. 다운스트림 작업에 대한 fine-tuning은 이런 trillion-scale model에서는 거의 효과가 없다. 심지어 many-shot fine-tuning setting 조차도 모델 사이즈가 너무 크기때문에 fine-tuning smaple을 빠르게 기억할 수 없다. → model scale이 너무 크면 fine-tuning이 의미가 없다
그래서 GPT-3와 DALL-E는 fine-tuning의 대체로 handcrafted로 만들어진 prompt를 활용하여 모델을 조정하고 있다. 그러나 이는 너무나 큰 validation set에 크게 의존하고, 성능도 불안전 하다.
- 아래 표에서 보면 한 단어의 변화가 급격한 차이를 일으킨다.

따라서 최근 연구는 mining traning corpus, gradient searching, using separate model을 사용하여 discrete prompt search를 자동화 하는데 집중하고 있다.
3. Method: P-tuning
Discrete prompt와 마찬가지로 P-tuning은 모델을 업데이트 하지 않는 선에서 적용한다.
Nevertheless, the P-tuning replaces the input embeddings of pre-trained language models with its differential output embedding
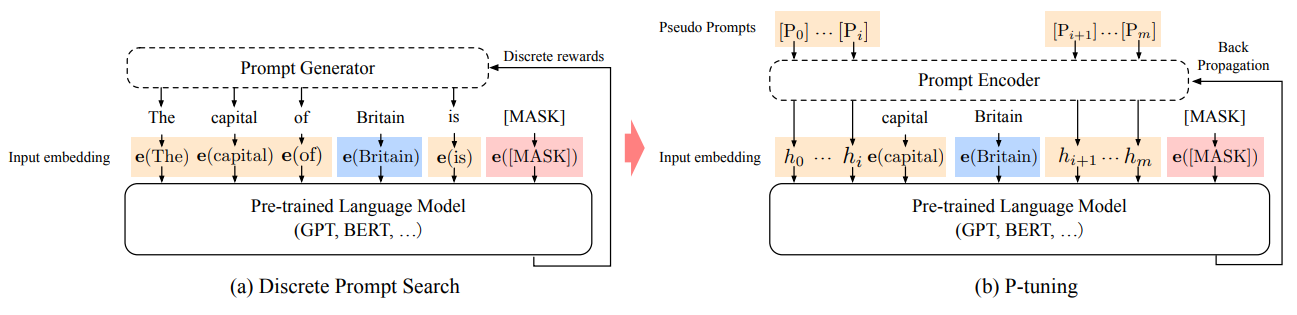
3.1. Architecture
symbol..
- $\mathcal{M}$: pre-trained model
- $x_{1:n} = {x_0, x_1, ..., x_n}$ : sequence if discrete input token
- $\{\mathbf{e}(x_0), \mathbf{e}(x_1), ..., \mathbf{e}(x_n)\}, \quad \mathbf{e} \in \mathcal{M}$: will be mapped to input embedding by the pre-trained embedding layer
- e.g. 사전 훈련 $x$는 마스크되지 않은 토큰을 참조 / $y$는 [MASK] 토큰을 참조
- sentence 분류에서 $x$는 문장 토큰을 참조 / $y$는 [CLS]를 참조
- $x$가 주어졌을 때, downstream의 처리를 위해 target token $y$의 출력 임베딩을 사용한다.
- prompt $p$: context $x$, target $y$ 및 그 자체를 템플릿 $T$로 구성하는 것입니다.

- $\mathcal{V}$: language Model $\mathcal{M}$의 vocabulary
- $[P_i]$ : 템플릿 $T$의 $i^{th}$ prompt token
template $T = \{[P_{0:i}], x, [P_{i+1:m}], y\}$라고 할 때, $[P_i] \in \mathcal{V}$

where $h_i(0≤i ≤m)$ are trainable embedding tensor. 이를 통해 $\mathcal{M}$의 $\mathcal{V}$가 표현할 수 있는 원래 어휘를 넘어 더 나은 continous prompt를 찾을 수 있다.
마지막으로 다운스트림 손실함수 $\mathcal{L}$로 우리는 다음을 통해 continous prompt $h_i(0≤i ≤m)$를 differentially optimize할 수 있다.
$$ \hat{h}_{0:m} = {arg min}_h \mathcal{L}(\mathcal{M}(x, y)) $$
3.2. Optimization
continous prompt를 훈련한다는 아이디어는 간단하지만 실제로는 두 가지 문제가 있다.
- Discreteness
- : $\mathcal{M}$의 원래 word embedding $\mathbf{e}$는 pre-training 후 이미 discrete되어 있다. 만약 $h$가 무작위 분포로 초기화된 다음, SGD로 최적화 되면 optimizer는 쉽게 local minima에 빠질 수 있다.
- SGD: Stochastic Gradient Descent, only change the parameters in a small neighborhood
- Association
- : prompt embedding $h_i$ value가 독립적이기 보다는 서로 의존해야한다.
⇒ P-tuning에서 우리는 Prompt encoder를 사용하여 Discreteness와 Association문제를 해결할 수 있는 lite한 neural network로 구성된 sequence로 h_i를 모델링 할 것을 제안한다.
model은 bidirectional long-short term memory network (LSTM), with a ReLU activation two-layer multilayer perceptron(MLP)이고, 언어모델 $\mathcal{M}$에 대한 실제 입력 임베딩 $h’_i$는 다음 식에서 파생됨
$$ h_i= MLP([\vec{h_i} : \gets \vec{h_i}]) \qquad \quad \ \ \ \ \qquad \qquad\\= MLP([LSTM(h_{0:i}) : LSTM(h_{i:m})]) $$
LSTM head의 사용은 일부 parameter를 추가하지만 추가된 크기가 사전 훈련된 모델보다 몇 배나 작으니 괜찮다. 또한 추론에서는 출력임베딩 $h$만 필요하고, 나머지 LSTM head는 폐기해도 된다.
또한 anchor token(고정 토큰)을 거의 추가 하지 않는 것이 SuperGLUE 벤치마크의 일부 NLU작업에 도움이 된다. RTE task의 경우 “?”가 prompt 템플릿에 존재하는데

이러한 anchor word는 각 구성요소를 특징짓는데 도움을 준다. 여기서 ?는 HYP가 질문 부분으로 작용함을 나타낸다.
4. Experiments
4.1 Knowledge Probing

- Maual Prompt < Discrete < P-tuning
- large scaled model에 대해 Fine-tuning은 OOM이 나는 반면 P-tuning은 높은 성능을 유지
4.2. SuperGLUE
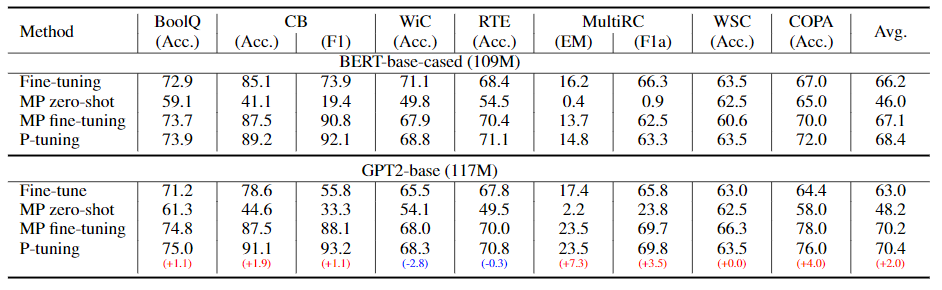
- Base-scaled model에 적용한 경우
- Fine-Tuninf < P-Tuning
- BERT < GPT
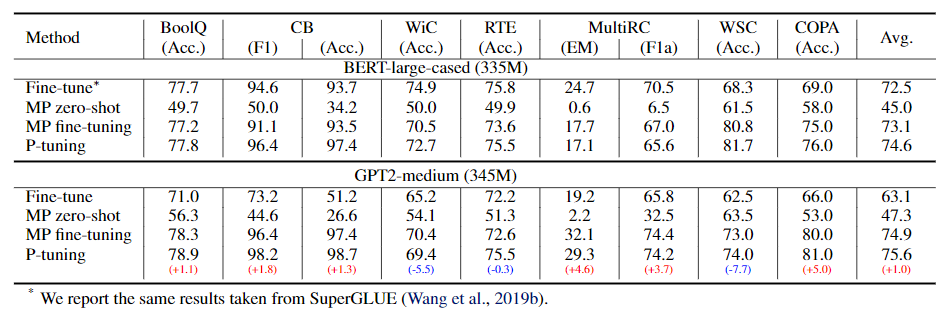
Large-scale model
'Deep Learning > Natural Language Processing' 카테고리의 다른 글
| Encoders and Ensembles for Task-Free Continual Learning 리뷰 (0) | 2022.03.11 |
|---|---|
| Prompt Learning 오픈소스: OpenPrompt 리뷰 (0) | 2022.03.11 |
| MASS: Masked Sequence to Sequence Pre-training for Language Generation 리뷰 (0) | 2022.02.22 |
| XML, Cross-lingual Language Model Pretraining 리뷰 (0) | 2022.02.22 |
| Transformers 가족 (BERT vs GPT vs GPT2) (0) | 2021.06.01 |



댓글