이 전 포스팅에서는 의사결정 나무의 여러 알고리즘을 정리하며 단점으로 과적합을 꼽았다. 과적합을 해결하기 위한 여러 방법 중 하나인 앙상블(Ensemble) 알고리즘을 설명하고 그 종류에 대해 알아보자.
앙상블(Ensemble)
- 앙상블은 여러가지 우수한 학습 모델을 조합해 예측력을 향상시키는 모델
- 장점: 단일 모델에 비해 분류 성능이 우수하다.
- 단점: 모델의 결과 해석이 어렵고, 예측 시간이 오래 소요된다.
많은 모델이 있기 때문에, 한 모델이 예측을 엇나가게 하더라도 어느 정도 보정이 되는 것이 장점이다. 즉, 보다 일반화(Generalized)된 모델이 만들어 지는 것이다.
단일모델로는 Decision tree, svm, deep learning model 등 모든 종류의 학습 모델이 사용될 수 있다.
Voting의 종류
최종 모델의 예측값을 결정짓는 voting은 크게 하드보팅(hard voting)과 소프트보팅(soft voting)으로 나눌 수 있다.

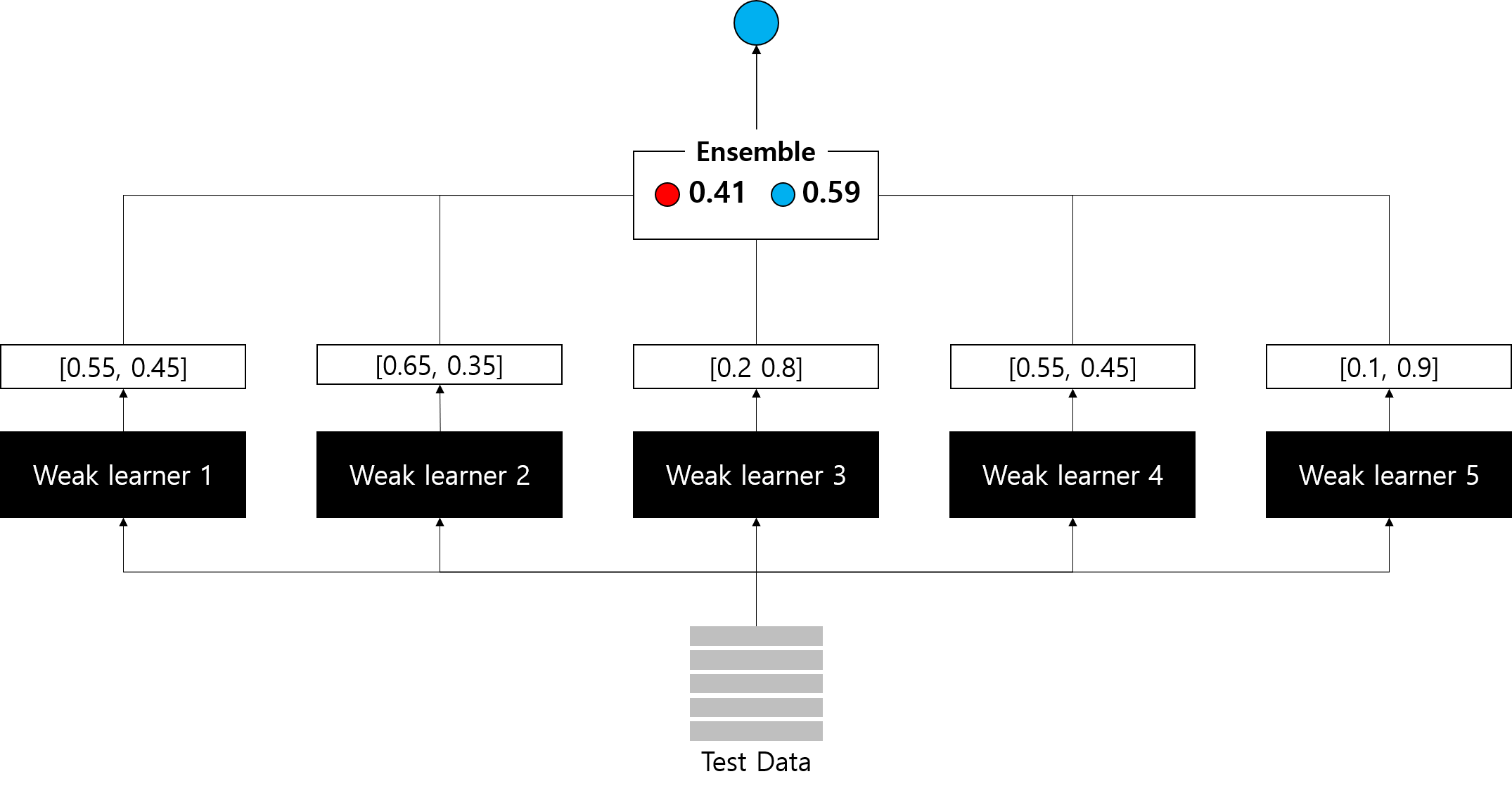
- 하드 보팅(Hard voting): 각 모델들의 예측 결과 값을 바탕으로 다수결 투표
- 소프트 보팅(Soft voting): 각 모델의 예측 확률 값의 평균 또는 가중치 합을 사용
- 어떠한 이유 (단일 모델에 사용되는 feature engineering 방법 등)에 의해 weak learner들에 대한 신뢰도가 다를 경우, 가중치를 부여하여 평균이 아닌 가중치 합 사용 가능
- 가중치는 임의로 부여할 수도 있고, 스태킹(Stacking) 기법을 사용할 수도 있음
앙상블의 종류

앙상블 알고리즘은 학습 방식에 따라 크게 배깅(Bagging), 부스팅(Boosting), 스태킹(Stacking)으로 나눌 수 있다.
| 분류 | 배깅(Bagging) | 부스팅(Boosting) |
| 공통점 | 전체 데이터 집합으로부터 복원 랜럼 샘플링(bootstrap)으로 훈련 집합 생성 | |
| 차이점 | 병렬학습 : 각 모델의 결과를 조합하여 투표 결정 |
순차학습 : 현재모델 가중치 -> 다음 모델에 전달 |
| 특징 | 균일한 확률 분포에 의해 훈련 집합 생성 | 분류하기 어려운 훈련 집합 생성 |
| 적용 목적 | Variance 감소 | Bias 감소 |
| 강점 | 과적합에 강함 | 높은 정확도 |
| 약점 | 특정 영역에서 정확도 낮음 | outlier(이상치, 결측치)에 취약 |
| *depth | 데이터의 분산이 클 때 overfit을 주어 변동성을 크게 만들어서 분산을 줄이는 효과를 볼 수 있다. => depth : 4, 5, 6, 7 (높게) |
depth: 2, 3, 4 (낮게) |
배깅(Bagging)
배깅(Bagging)은 Bootstrap Aggregating의 약자.
부트스트랩 (Bootstrap) 이란?
- 원래의 데이터셋으로부터 관측지를 반복적으로 추출(복원 반복 추출)하여 데이터 셋을 얻는 방법
- 데이터 양을 임의적으로 늘리고, 데이터 셋의 분포가 고르지 않을 때 고르게 만드는 효과가 있다.
- 데이터 샘플링 시 편향을 높임으로써(중복 허용) 분산이 높은 모델의 과적합을 줄이는 효과를 준다
- 부트스트랩을 사용하지 않으면 모두 동일하게 n개의 데이터로 학습 -> 동일한 분류 모델을 가짐
부트스트랩을 통해 만들어진 여러 데이터셋을 바탕으로 weak learner를 훈련시킨 뒤, 결과를 voting한다.
- Random Forest

부스팅(Boosting)
부스팅은 반복적으로 모델을 업데이트 한다.
- 잘못 분류된 객체들에 집중하여 새로운 분류규칙을 생성하는 단계를 반복하는 알고리즘 (순차적 학습)
- 오분류된 개체는 높은 가중치, 정분류된 개체는 낮은 가중치를 적용 -> 예측 모형의 정확도 향상

Boosting은 다시 AdaBoost(Adaptive Boosting)와 GBM(Gradient Boosting Model) 계열로 나눌 수 있다.
스태킹(Stacking)
기본 스태킹 모델
스태킹(Stacking)은 개별 알고리즘의 예측한 데이터를 기반으로 다시 예측을 수행하는 방법이다.
정리하면 개별 알고리즘이 예측한 결과를 최종 메타 데이터 세트로 만들어 별도의 ML 알고리즘으로 최종 학습을 수행하고 테스트 데이터를 기반으로 최종 예측을 수행하는 방식이다.
스태킹 방식에 사용되는 모델은 크게 기반 모델과 메타 모델로 구분된다.
기반 모델이란 1차 예측을 수행하는 개별 알고리즘을 의미하며 메타 모델은 기반 모델의 예측 결과를 최종 데이터 세트로 학습하는 별도의 ML 알고리즘이다.
과적합 방지를 위해 주로 k-fold cross validation을 이용한다.

CV 세트 기반의 스태킹 모델
위의 스태킹 모델에 사용된 메타 모델은 결국 y_test를 학습했기 때문에 과적합 문제가 발생할 수 있다. 따라서, CV 세트 기반의 스태킹 모델은 이를 방지하고자 교차 검증 기반의 예측 결과 데이터세트를 이용하는 방법이다.
즉, 개별 모델이 교차 검증을 통해서 메타 모델에 사용되는 학습, 테스트용 스태킹 데이터셋을 생성하여 이를 기반으로 메타 모델이 학습과 예측을 수행하는 방식이다.
cv 세트 기반의 스태킹 모델의 원리
- Train set을 N개의 fold로 나눈다. (3개의 fold로 나누었다 가정)
- 2개의 fold를 학습을 위한 데이터 폴드로, 1개의 fold를 검증을 위한 데이터 폴드로 사용
- 위의 2개의 폴드를 이용해 개별 모델을 학습, 1개의 검증용 fold로 데이터를 예측 후 결과를 저장
- 위 로직을 3번 반복(학습, 검증용 폴드를 변경해가면서) 후 Test set에 대한 예측값의 평균으로 최종 결괏값 생성
- 위에서 생성된 최종 예측 결과를 메타 모델에 학습 및 예측 수행

Reference
- https://joyfuls.tistory.com/61
- https://deepflowest.tistory.com/164
- https://tyami.github.io/machine%20learning/ensemble-1-basics/
- http://www.dinnopartners.com/__trashed-4/
- https://quantdare.com/what-is-the-difference-between-bagging-and-boosting/
- https://kimdingko-world.tistory.com/186#CV-%EC%84%B8%ED%8A%B8-%EA%B8%B0%EB%B0%98%EC%9D%98-%EC%8A%A4%ED%83%9C%ED%82%B9
'Machine Learning' 카테고리의 다른 글
| 부스팅 앙상블 (Boosting Ensemble): AdaBoost (0) | 2022.04.05 |
|---|---|
| 배깅 앙상블 (Bagging Ensemble): Random Forest (0) | 2022.04.04 |
| 의사결정 나무 (Decision Tree) ID3 알고리즘 (0) | 2022.04.04 |
| 의사결정나무, Decision Tree (0) | 2022.04.04 |
| 분산과 편향 차이 이해하기 (bias vs variance) (0) | 2022.04.04 |




댓글