지도학습 -> labeled data
비지도 학습 -> unlabeled data를 통한 학습,
- e.g. clustering, constrative learning
- 비지도학습의 핵심은 알고리즘의 성능을 올바르게 측정하는 것.
Clustering 평가 지표
1. Silhouette Score
Silhouette score는 군잡 간 separation distance를 측정하는데 사용한다. 즉, 군집의 각 점이 인접한 군집의 점에 얼마나 가까운지 나타내는 측도를 표시한다. 측정값의 범위는 [-1, 1]이며 "similarities within clusters and differences across clusters"를 시각적으로 표현 가능하다.
실루엣 점수는 각 표본의 mean intra-cluster distance $i$와 mean nearest-cluster distance $n$을 사용하여 계산된다.
The Silhouette Coefficient for a sample:
$$(n-i)\over \max(i, n)$$
- $n$은 각 표본과, 표본이 포함되지 않은 가장 가까운 군집 사이의 거리
- $i$ 각 군집 내 평균 거리
Silhouette Plots은 y축에 있는 cluster label을 나타내며, x축에는 실제 실루엣 점수를 나타낸다. 실루엣의 크기/두께도 해당 군집 내의 표본 수에 비례함

- Silhouette Coefficients가 높을 수록(1에 근접), 군집의 표본은 인접한 군집과의 거리가 멀다.
- 값이 0이면, 두 인접 군집 사이의 결정 경계에 있거나 매우 가깝다.
- 낮으면(-1에 근접), 해당 표본이 잘못된 군집에 할당되었음을 나타냄
실루엣 계수를 평균하면 단일 값으로 전체 모집단의 성능을 설명 가능 : Global Silhouette Score
python으로 계산하기 위해 아래 sklearn 코드를 작성
sklearn.metrics.silhouette_score(X, labels, *, metric='euclidean', sample_size=None, random_state=None, **kwds)
2. Rand Index, RI
예측된 군집과 실제 군집의 표본 쌍을 고려한 두 군집 사이의 유사성 측도
The formula of the Rand Index is:
$$RI = {Number\ of\ Agreeing\ Pairs \over Number\ of\ Pairs}$$
- [0, 1]
- ground-truth가 있다고 가정 -> 완벽한 비지도학습이 아니다.
python으로 계산하기 위해 아래 sklearn 코드를 작성
sklearn.metrics.rand_score(labels_true, labels_pred)
3. Adjusted Rand Index
“adjusted for chance”
$$ARI = {RI - Expected\ RI \over \max{RI} - Expected\ RI}$$
- [0, 1]
python으로 계산하기 위해 아래 sklearn 코드를 작성
sklearn.metrics.adjusted_mutual_info_score(labels_true, labels_pred, *, average_method='arithmetic')
4. Mutual Information, MI
동일한 데이터의 두 레이블 간의 유사성에 대한 측도
Mutual Information between clusters $U$ and $V$ is given as:
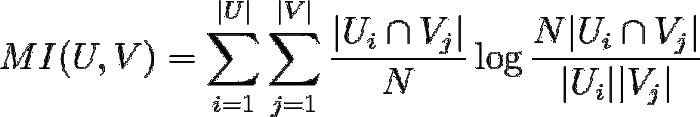
- $|U_i|$ : 클러스터 $U_i$의 샘플 수
- $|V_j|$ : 클러스터 $V_j$의 샘플 수
RI와 유사하게 해당 지표는 분포에 대한 ground truth labels을 알아야 함.
python으로 계산하기 위해 아래 sklearn 코드를 작성
sklearn.metrics.mutual_info_score(labels_true, labels_pred, *, contingency=None)
5. Calinski-Harabasz Index
Variance Ratio Criterion 라고 알려져있다.
이는 within-cluster dispersion과 between-cluster dispersion의 비율로 정의된다. C-H 지수는 ground truth labels를 필요로 하지 않기 때문에 클러스터링 알고리즘의 성능을 평가하기 위한 좋은 도구이다.
지수가 높을수록 성능이 우수함을 의미한다.
The formula is:
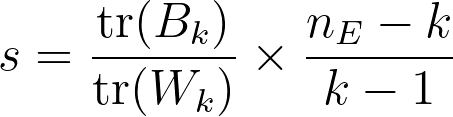
여기서 $tr(B_k)$s는 between group dispersion matrix의 trace(대각합) 이고, $tr(W_k)$는 within-cluster dispersion matrix의 trace이다. 아래와 같이 정의된다.
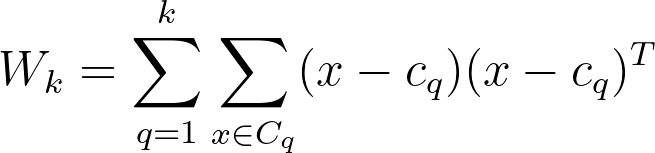
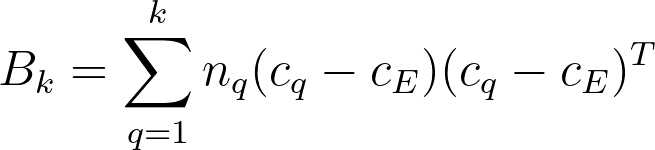
python으로 계산하기 위해 아래 sklearn 코드를 작성
sklearn.metrics.calinski_harabasz_score(X, labels)
6. Davies-Bouldin Index
가장 유사한 군집을 가진 각 군집의 평균 유사성 측도로 정의된다.
- 유사성은 within-cluster distances와 between-cluster distances의 비율이다.
- 더 멀리 떨어져 있고, 덜 분산된 클러스터는 더 나은 점수를 얻을 수 있다.
- 최소점수 : 0
- 낮을 수록 클러스터링 성능 향상
python으로 계산하기 위해 아래 sklearn 코드를 작성
sklearn.metrics.davies_bouldin_score(X, labels)
0. Reference
'Machine Learning' 카테고리의 다른 글
| 부스팅 앙상블 (Boosting Ensemble): AdaBoost (0) | 2022.04.05 |
|---|---|
| 배깅 앙상블 (Bagging Ensemble): Random Forest (0) | 2022.04.04 |
| 앙상블 (Ensemble)의 개념 (1) | 2022.04.04 |
| 의사결정 나무 (Decision Tree) ID3 알고리즘 (0) | 2022.04.04 |
| 의사결정나무, Decision Tree (0) | 2022.04.04 |




댓글